
In the world of artificial intelligence (AI), the recognition of handwritten digits proves that you got your neurons right and in working condition. This application of AI is already quite old – its breakthrough came in 1989 when a reliable machine-enabled parsing of ZIP codes for postal services was achieved. Soon after, it was proven that multi-layer feed-forward networks can implement any function. Shortly, financial institutions adopted the technique for the automatic parsing of account numbers on remittance slips for wire transfers or bank checks. Today the recognition of handwritten digits using different AI-techniques is also famous in academia for teaching and learning purposes.
Recognition of Handwritten Digits is Complex

While the presentation of the problem itself has not changed over the years, computing power has increased dramatically during recent decades, making it now possible to run the recognition on an FPGA (Field Programmable Gate Array) board suitable for teaching, together with a small digital camera. Nevertheless, it is still one of the harder tasks for an artificial intelligence to tackle. Handwritten digits differ in size, width, and orientation, and each person’s handwriting has distinct variations. Different cultures even write digits differently. There are, for example, subtle differences on how Americans and Europeans write the digits 1, 4, or 7.
Another area raising digit recognition issues are the similarities between some digits: 3 and 8, 0 and 8, 5 and 6, 2 and 7, etc. Last but not least, the quality of the image itself has a large influence. If not properly trained, the AI will incorrectly classify too many digits for the final product to be of any use. Trying to implement such a recognition system using the classical programming approach will get the programmer in a lot of trouble with a lot of details and special cases.
Implementing a Textbook Version
But how does the recognition work? Looking at it from a very high-level, it’s straightforward: An image of the digit needs to be captured, processed and analyzed, and the result presented to the user.
Performing a more thorough analysis, it soon becomes obvious that many more tasks have to be executed and problems solved. The hardware for such a system is not the real obstacle. Digilent, for example, implemented a textbook-version of the digit recognition through artificial intelligence as a proof-of-concept using their 5 megapixels Pcam 5C fixed-focus color camera module for the image capture, their Zybo Z7 Xilinx Zynq-7000 ARM/FPGA development board, and its Pmod MTDS multi-touch display system as user interface and to display the result of the recognition process (the whole setup is available at a discount in our Embedded Vision Bundle).

Once the Pcam 5C has captured an image of a digit at a size of 1,000 by 1,000 pixels (which actually is an overkill for this application), it will send it to the Zybo Z7 through the MIPI CSI-2 interface (MIPI Camera Serial Interface 2) and be pre-processed on the FPGA there. Here it will be scaled down to 500x 500 pixels, converted into greyscale, and finally binarized into black-and-white.
Further processing takes place on the 667 MHz dual-core ARM-Cortex-A9 processor where a bounding box search – the search for the smallest frame containing the digit – is performed, the digit centered in the bounding box (centering it by the center of mass within a larger window would have been another possibility) and the bounding box scaled to an image size of 28 by 28 pixels. This size was chosen, as the training set for the neural network uses this resolution.
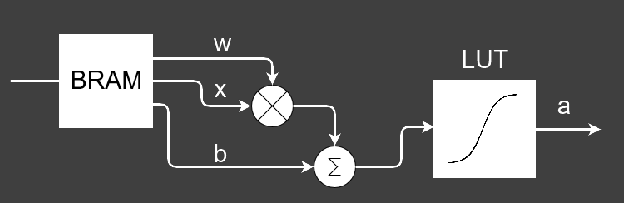
From this image, each pixel is used as input to one of the 784 (28 x 28) input neurons of the feedforward artificial neural network (ANN) on the FPGA. Each neuron there uses a fixed-point Q4.11 representation and consists of a multiplier, multiplying the input pixel width the weight derived from the training and one adder adding the bias – also created by the training data – to the multiplication result (see above image). Finally, a sigmoid function is used to create the activation output of the neuron. Equations 1 and 2 give the mathematical details:
a= σ(w∙x+b) (Equation 1)
σ(z)= 1/(1+e^(-z) ) (Equation 2)
where w is the weight, b the bias, and the sigmoid function.
The activation output of the input layer is then used as input to all of the 16 neurons of the first hidden layer, with the mysteriously sounding term “hidden layer” meaning that the neurons belonging to that layer are neither input nor output neurons. The output of the hidden layer 1 is then used as input to all neurons of the second hidden layer, also consisting of 16 neurons. With two hidden layers, the system technically qualifies as a deep neural network (deep learning), but it cannot be compared to other systems with several thousand layers.
Each Output Neuron Corresponds to One Digit
The output layer finally consists of 10 neurons, one for each digit in the [0…9] range. Each output neuron has an activation value and the neuron with the highest activation value is considered the correct guess. If, for example, the output neuron representing the digit 4 has the highest value, we consider the digit 4 as the best guess of the recognition.
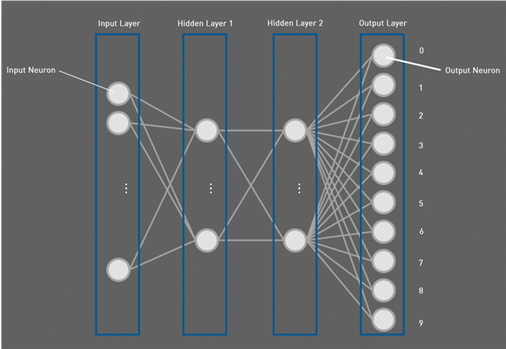
As the outputs of the neural network are not probabilities per se, the degree of certainty of the result cannot be told. But this could be solved by adding a Softmax layer to the network, which turns numbers into probabilities. The final result of the recognition is then displayed on the Pmod Multi-Touch Display System.

Training is Most Important
As with all artificial neural networks, the system needs to be trained before it can be used. In case of our example, the universality theorem was applied to compute the weights and biases from images in the widely used MNIST-(Modified NIST-)data base, which comprises 60,000 training images and 10,000 testing images, both sets with labeled images of handwritten digits in the range from zero to ten. The data base is called MNIST, as it is a subset of the data sets collected by NIST, the United States National Institute of Standards and Technology. The training was supervised and performed on a PC using Python. Each training set is a pair of input and the desired output and the training algorithm was taken from the open-source textbook from Michael A. Nielsen[1].
What was Achieved?
Once trained, the recognition rate of the trained artificial neural network on the MNIST test images reached 95.2%. Higher rates can be achieved if a convolutional neural network (CNN) is used. The best academical results with an error rate of 0.23% have been achieved with a hierarchy of 35 convolutional neural networks, something which would have been beyond the scope of this proof-of-concept. It also turned out that the live recognition rate highly depends on the digit skew, as automatic de-skewing was not implemented, but manually performed. The most critical digit turned out to be the digit “9”, which was rarely recognized by the demonstrator. Once turned, it was mostly recognized as “6”, something which points to the fact that retraining the system should help.
Pre-processing took 1664 ms, if done solely on the dual-core ARM-Cortex-A9 processor on the Zybo Z7 development board from Digilent and 999 ms if performed on the ARM-core and the FPGA. Execution time of the artificial neural network was 73 ms on the ARM and 57 ms if done on ARM plus FPGA.

This textbook-implementation of a handwritten digit recognition using a low-cost FPGA-board demonstrated that is it possible to implement such an artificial neural network with deep learning on such a system. The Xilinx Zynq-7000 ARM/FPGA development board, together with the Pcam 5 and the Pmod MTDS display – all from Digilent and available at a discount in the Embedded Vision Bundle –allows to simply take a textbook and to implement a live capture and inference system from scratch.
[1] Michael A. Nielsen, „Neural Networks and Deep Learning”, Determination Press. 2015 (http://neuralnetworksanddeeplearning.com/chap1.html)
Thank for sharing! This is a really interesting discussion.
Hello guys, very interesting article, thanks for that. Do you have any code about the implementation of the Neural Net to share?