
Welcome Back!
Now that we know about recursion, we can talk about an important topic in programming — recursive sorting algorithms!
If you check out the pointers blog post, we go over bubble sort, an iterative sorting algorithm. The problem with bubble sort is that it has an average time complexity of O(n^2), meaning that for every n items, it takes n^2 operations.
Today, we’re going to go over quick-sort and merge-sort, both of which have an average time complexity of O(n*log(n)). What’s the difference between O(n^2) and O(n*log(n))? Let’s make a small chart to show the differences.
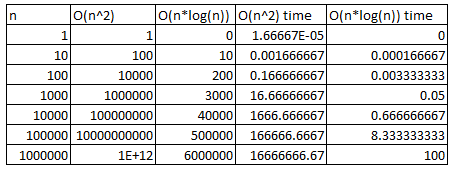
The time sections on the right assume that our computer can do one operation every one one-thousandth of a second (which is slow by modern standards, but still shows the differences well). When “n” is very large (say a million), the O(n^2) algorithms will take about 31 years to complete (or till 2046), while the 0(n*log(n)) will take about 100 minutes, which is pretty reasonable for sorting a million items.
So why even bother with bubble-sort if there are sorting algorithms that are so much more efficient? Bubble-sort does have advantages, especially if space is an issue. But today we aren’t really going to worry about that.
Merge-Sort
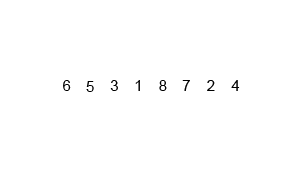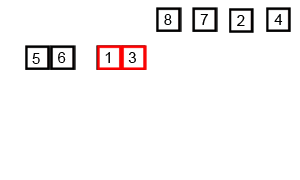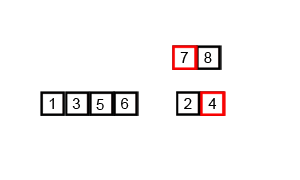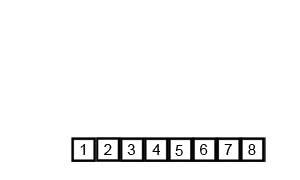
Credit to the Wikimedia Commons.
{kind=link}
Mergesort is a divide-and-conquer algorithm that divides an array of length n into n subarrays, and then recombines them using merge. Our Mergesort has two main functions: mergesort and merge.
mergesort

Mergesort is our recursive call, we take our array that has been passed into mergesort, then we divide the array into two halves and call mergesort recursively. This continues until each array has a size of 1. Then we return and merge (conquer). If we check out the code before we call mergesort again, you can see that there is the base case, and after that, the array list is being divided and moved into two smaller arrays.

Merge takes two arrays, and combines them. The two arrays have both been sorted by a previous call (except arrays with size 1, which can’t really be sorted). Then the arrays are sorted by checking the lowest value and moving them into a third array. The mergesort gif above is a really good way to show how merge sort works.

Mergesort Code
Here we have a small main that calls mergesort!
Quicksort
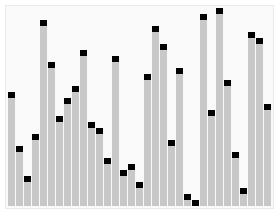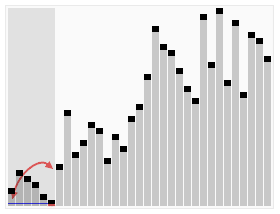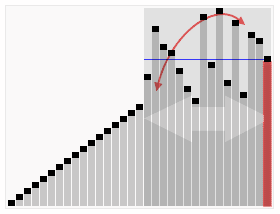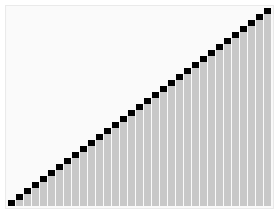
Credit to Wikipedia.
Instead of dividing an array into N subdivisions like mergesort, quicksort uses partitions to divide the array into subarrays. The division of the subarrays is decided by the pivot point, which is decided by the algorithm (like the first or last variable in the array), then move all the values less than the pivot point to one side, and the higher values to the other side. Our quicksort implementation has four functions in it: swap, partition, and two quicksorts (one is just for ease of use).

Swap is a small function that switches to values of a list using the input parameters left and right.

Partition is the “meat” of quicksort, and our implementation of quicksort takes the first value of low to use as the pivot point, and divides the array based of the point.

Our quicksort functions are not too difficult, most of the work is done in partition. Here we call partition to divide list, and then call Quicksort recursively until we reach our base case. If you check out our main for Mergesort main, we call mergesort(B, N). We’ve changed this in quicksort by using function overloading, now in our main we can either call quickSort(list, 0, N-1), which will start partitioning at 0 and N-1, or quickSort(list), which then calls quickSort with the partition calls.

Quicksort Code
Here’s an example of us calling quicksort!
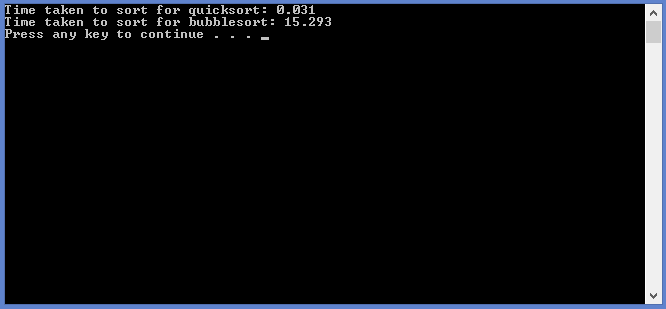
Comparison code
Here is an efficiency comparison between quicksort and bubblesort. Using 50000 randomly generated values, we can time how long each function takes to sort the same array. The time is displayed in seconds, so you can try it out yourself!
(Note: You can change N to more or less, and this will make change the amount of values to be sorted. 50000 was a good number to show the differences.)
I made an alternative visualization at https://thewalnut.io/visualizer/visualize/3474/334/ , you can see more clearly how the partition step is made (the example uses the 3-way partition), and how the recursive calls are made.
That’s pretty awesome Daniel!
-Josh
I’m trying to run mergesort with the following array (14,7,3,12,7,11,6,2)
Can someone help me with the following:
1. What are the values of list, lower, higher, left right, and k during the first 5 recursive calls?